In this post I'll go over how I put subtitle files (.srt files) to good use. I'll use the film "Contagion" with Turkish subtitles as my example throughout.
There are many, many websites that house all sorts of subtitles for most popular films - too many to list here, but I'll mention that I got the subtitle file from a website called Subtitlesbank.
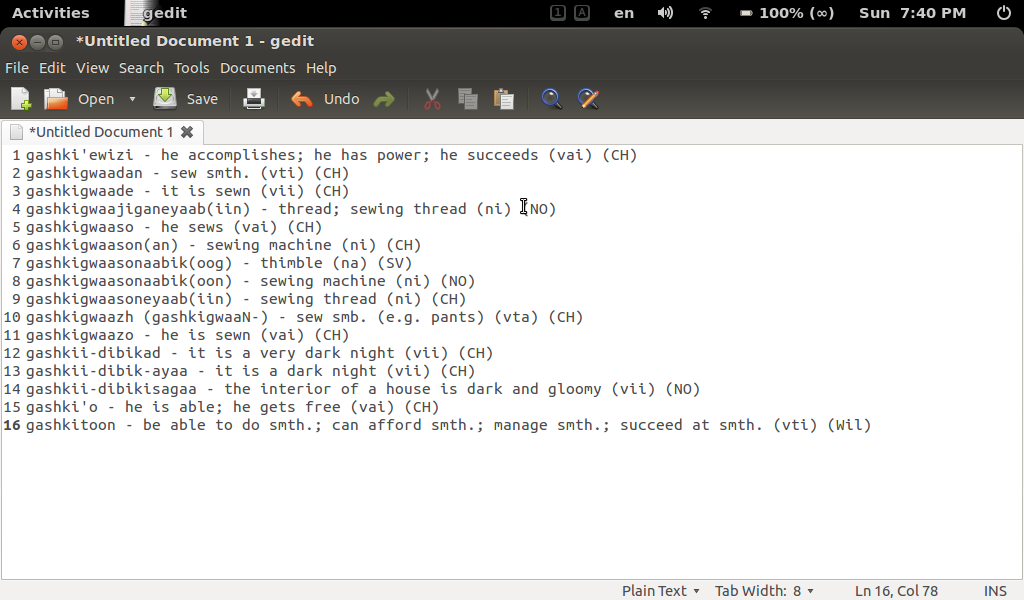
Once the .srt file is downloaded, it'll look something like this:

A couple of things to notice about the file: First, it's got timecode in it, which isn't useful for my purposes, so I'll strip the timecode out of the file. Since I use Linux, bash shell commands come in handy, but this can also be done in Windows and Mac, too. For Windows, a set of tools called Cygwin needs to be installed, while Mac users already have the tools needed.
To strip the timecode from the file, simply type in:
awk '/-->/{for(i=1;i<d;i++){print a[i]};delete a;d=0;next}{a[++d]=$0}END{for(i in a)print a[i]}' filename.srt > newfilename.txt
with "filename.srt" being the original .srt file and "newfilename.txt" being the new file without timecode.
The second problem with the file is the ascii encoding. Looking at the above screenshot, I've highlighted a line that has some funky letters that need to be changed throughout. That's easy enough to do with any decent text editor with a Find/Replace All command. I also got rid of any hypertext markup ("<i>" and "</i>") using the same method. Once I'd done that, the resulting file looks like this:

Much easier to read, and, more importantly, this new file can now be imported into Learning With Texts or another language-learning program.

Here's a screenshot:

This particular screenshot is just a simple text editor with GoldenDict, but any other text reader will do fine with GoldenDict, too, whether it's for Epubs or PDFs.
Subtitle files are a great way to do some light reading. Typical subtitle files for TV shows have around 500 or so sentences, while feature film subtitle files contain 1000 or more for moderate dialog.
Since I have Stardict (GoldenDict compatible) on my mobile device, it's also a good alternative to firing up Anki in my wasted minutes throughout the day.